
La irrupción de la inteligencia artificial (IA) en los procesos educativos y de creación artística ha abierto un campo de posibilidades técnicas y expresivas sin precedentes.
Consideramos que, en este nuevo escenario, lxs estudiantes de las carreras de artes -como así también el cuerpo docente- enfrentan el desafío de incorporar estas herramientas de manera crítica y ética, desarrollando una comprensión profunda de sus implicancias tanto estéticas como políticas, e incluso ambientales.
Es por esto que desde la Secretaría Académica de la Facultad de Artes, a través del Pameg y la Of. de Tecnología educativa, dialogamos con Matías Eduardo Bordone sobre las principales diferencias entre la Inteligencia Artificial tradicional y la Inteligencia Artificial Generativa, qué cambia cuando buscamos algo en un buscador tradicional y cuando usamos buscadores con IA integrada, qué son los modelos de lenguaje, qué sesgos se generan, qué recaudos tener en cuenta y mucho más.
Matías Eduardo Bordone es Licenciado en Ciencias de la Computación y Profesor de Informática. Ingeniero en IA en la industria. Activista de los derechos digitales, software y cultura libre en Cybercirujas, Libre Base y Vía Libre.
¿Qué diferencias hay entre inteligencia Artificial tradicional e Inteligencia Artificial Generativa?
Yo sé que es bastante complicado porque hay un montón de términos que si uno no está en el ambiente parecen todos lo mismo, pero a mí siempre me ordena tener un pequeño mapa y charlar un poco de qué relación hay entre diferentes conceptos como para poder diferenciar y y entender de qué se trata. No es lo mismo inteligencia artificial que machine learning, que data science, que big data o que deep learning.
Son un montón de palabras que uno a veces se pregunta si son lo mismo pero no. Sin embarog, hay relaciones muy cercanas una con la otra. En particular, me gustaría empezar por el concepto de inteligencia artificial. Hay un libro muy clásico que se llama Inteligencia artificial, un enfoque moderno, que en el primer capítulo da mínimo cuatro definiciones de inteligencia artificial. Por tanto, si escuchan distintas definiciones de inteligencia artificial es normal, es lógico.
Ni siquiera la legislación de la Unión Europea cuando hace la regulación sobre inteligencia artificial que que está en este momento, es superclara sobre qué se entiende por inteligencia artificial.
La definición que a mí me sirve para empezar, para poder empezar a discutir es una que dio uno de los de los precursores del área de inteligencia artificial que fue Alan Turing. Hoy lo conocemos como test de Touring. Se trata de una prueba que dice que si yo pongo en una computadora y una persona a interactuar con otra persona y esta segunda persona es incapaz de distinguir quién es quién, es decir, si la computadora es es persona o la persona es computadora, si no es capaz de distinguir cuál de las dos es persona o cuál de las dos es computadora, entonces, estamos hablando de que interactúa con una computadora inteligente, con una inteligencia artificial. Lo que intenta hacer en ese momento Turing es como empezar a darle un marco, alguna alguna definición de que no cualquier cosa es inteligencia artificial. Y en este caso para hacer una prueba rápida y descartar y separar peras de melones, vamos a decir que si se porta como inteligente o como humano, entonces es inteligente.
Notamos aquí que la primera definición de inteligencia artificial en estos términos es comparada al humano. Es cierto que esas definiciones son de cerca de 1930. ¿Pasó tiempo de eso no? Y creo que avanzamos bastante. Pero hay que identificar que no todo programa de inteligencia artificial está basado en datos. Puede ser cualquier cosa.
Por ejemplo, había un chatbot que se llamaba Elisa en su momento que estaba basado en reglas, que estaba programado de forma tradicional diciendo reglas. Si si te dice esto, contestale esto otro, si te dice esto otro contestale. Eso en dentro del mundillo es inteligencia artificial, aunque no se haya utilizado datos para entrenarlo.
La parte de inteligencia artificial que es basada en entrenamiento en datos o aprender patrones de los datos que se está trabajando es el machine learning, aprendizaje maquínico, una traducción medio rara, pero la pueden encontrar es «Yo tengo una tarea y tengo un programa que tiene que resolver esa tarea. Si el programa puede mejorar la performance en esa tarea a partir de la experiencia, es decir, a partir del análisis de datos, entonces podemos decir que está aprendiendo. Es la definición de aprendizaje de Tom Mitchell. Tenemos datos, la computadora aprenden patrones de esos datos y después se utilizan para cosas, para resolver un problema y siempre tienen algún problema en particular.
Fuera de eso, fíjense que en el diagrama yo le estoy marcando ahí que no todo lo que está basado en datos es machine learning, no hay toda un área que se llama data science, que data science sí
tiene que ver con ciencia de datos, pero hay cosas que tienen que ver con la ciencia de datos como analíticas, informes, reportes, data representation y cosas por el estilo que son parte de data science, pero que no son específicamente machine learning.
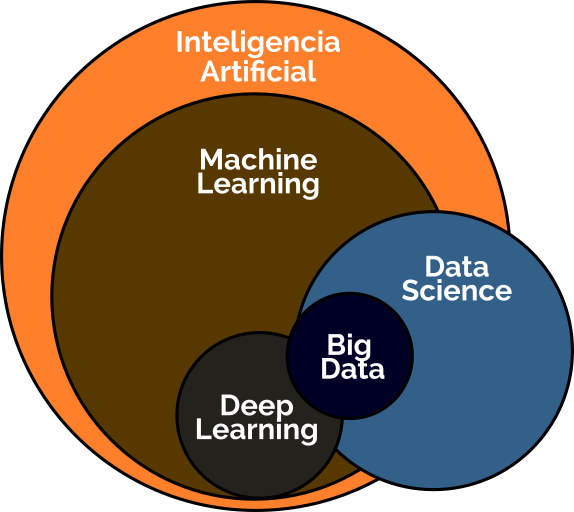
Contanos qué es el Big Data y de deeplearning que vemos en ese diagrama
Para mí una regla que me sirve interesante es decir, si tengo datos que me entran en mi computadora, entonces no es big data.
Realmente recién estamos empezando a hablar de big data cuando eh no me entran los datos en la computadora. necesito más de una computadora, necesito redes, necesito servidores, necesito todo ese tipo de cosas para poder procesarlo. Recién ahí podemos decir eso es bigdata.
Junto con esto, la última definición que les quería traer tenían que ver con lo que se llama deep learning, que es un término que está muy de moda hoy en día.
En realidad, deep learning tiene que ver con las redes neuronales, conceptos que son del campo de la física que tienen que ver con intentar hacer una representación de la neurona humana.
En los últimos años se dio un avance muy importante, un concepto que no es cualquier red neuronal, sino lo que llaman deep learning, que es tener como muchas capas de neuronas que se le dicen para resolver un problema y eso es lo relativamente moderno que ha habido hace poco, y que hace la diferencia con lo que eran las redes neuronales de 50, 60, 70.

¿Qué diferencia podemos señalar entre la IA tradicional y la IA generativa?
Las inteligencias artificiales generativas no tienen que ver con que yo le dé un dato y me diga qué característica tiene o qué propiedad tiene o me resuelve un problema. Intenta generar nuevos datos que sean parecidos a los datos anteriores. El objetivo de la IA generativa es generar datos nuevos a partir de los patrones que habrá encontrado en los anteriores. Veamos algunas grandes marcas conocidas de este tiempo:

¿Qué son los modelos de lenguaje?
Voy a separar generación de imagen y generación de texto. En el caso de los modelos de lenguaje que generan texto, quizá ni sabemos lo que son pero tenemos experiencia de los mismos. Absolutamente todos los que alguna vez tocamos un celular tuvimos experiencia con los predictores de texto. Los celulares tienen todos un predictor de texto y que yo voy escribiendo y me trate de adivinar cuál es la próxima palabra que voy a escribir.
Eso básicamente es un modelo de lenguaje superrudimentario, pero funcionan así. Con ChatGPT lo mismo, pero con muchos esteroides.
Entonces, cuando yo escribo, por ejemplo, en el celular «me voy a» el celular intenta adivinar cuál es la próxima palabra que voy a poner, que es dormir, morir o matar, por ejemplo.
Podrían ser palabras que siguen después de «me voy a». En cambio, si yo le pregunto a chat GPT, completá la frase «me voy a» dice, «Tomar un café para recargar energías, ¿querés que te dé varias opciones?»
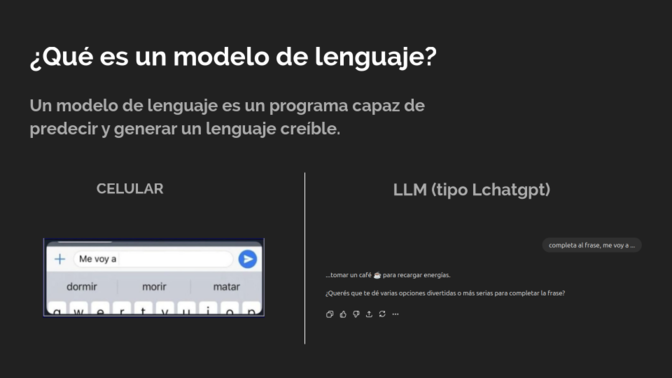
Lo que va haciendo es agregando letra por letra o palabra por palabra de la oración que ya venía antes. Solo que como tiene mucho sentido porque se acuerda de todo el resto de la frase que había antes, es como que va escribiendo en el momento.
¿Cómo hace ChatGPT para poder hacer esto?
Es importante mencionar que chat GPT y todos los otros modelos de lenguaje grandes son precisamente se llaman LLM, Lash Language Models. El juego que juegan es tratar de adivinar la palabra, la letra que sigue, la instrucción que sigue o todo ese tipo de cosas. ¿Qué pasa si yo digo, «Lo tengo en la mm de la lengua?» Seguramente pondrías «punta» Sería muy raro que alguien piensa otra palabra. Lo que hacen los modelos de lenguaje es analizar grandes cantidades de datos, de información, de texto que están dando vueltas y en cierta forma lo que hacen es sacarle probabilidad. La probabilidad que vaya la palabra punta, por lo menos para lo que yo he escuchado toda mi vida y lo que he leído toda mi vida, es altísima. Y la palabra, por ejemplo, lo tengo en la zángano de la lengua, tendría una probabilidad muy baja nunca en mi vida, creo yo. Agarra y dice, «Puo escribir, lo tengo en la y se fija en una tabla que tiene, no, no es una tabla, pero se hace unos cálculos matemáticos y calcula la probabilidad de cada una de las palabras que siguen. Chat GPT se fija en la probabilidad. Dice, «O las 10 palabras más probables son estas 10.» Y le pone alguna. Entonces, eso responde un poco, me parece interesante, por qué uno cuando escribe algo en chat GPT o en algún otro lado, la misma oración varias veces va generando frases distintas y es un poco por eso, porque en realidad no te da la palabra más probable, porque si te diera la más probable siempre haría la misma oración. En realidad juega, te dice, mira, tengo 10 palabras más probable y tomo, qué sé yo, aleatoriamente alguna de esas 10 para continuar. Para esto lo que tiene que hacer es analizar muchísimos datos.
Quiero mostrarles lo que llamamos nosotros una red neuronal. Le doy de comer la oración que yo ya tengo hasta ahora. Y hay ahí unas funciones que hacen que pasen a las otras bolitas que son las celestes y te dice, «Che, mira, tiene esta palabra, esta palabra, esta palabra.» Entonces hace unos cálculos que están más a la derecha que voy a mostrar y a la salida la amarillita me diría, bueno, la palabra que sigue de esa oración es punta.
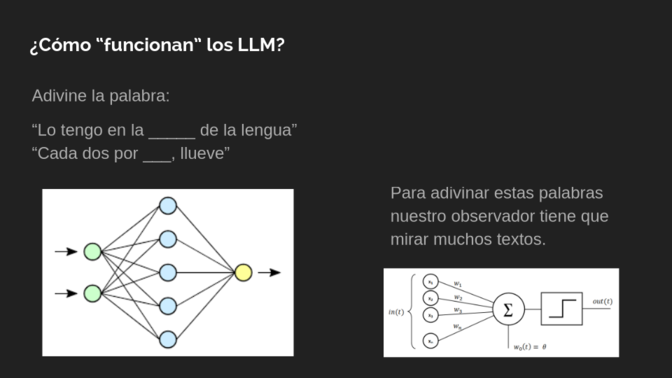
Por ejemplo, si yo le le doy de comer, lo tengo en la hace todos esos cálculos y en la parte amarillita me contesta punta. Y después vuelve a hacer lo mismo, vuelve a meterlo en la parte verde, lo tengo en la punta, lo que sigue de y así sucesivamente me va generando toda una oración. Y lo que está a la derecha, eh, fíjense que tiene como unas letritas que dice W1, W2, W3.
Esto es lo que nosotros llamamos en la computación una neurona, pero no es una neurona, es un modelito, una representación matemática que nosotros llamamos de una neurona. Y fíjense que lo que hacemos nosotros es con estos números es hacer como una especie de multiplicación W1, W2, W3, W hasta WN. Es como si yo tengo N nas por cuánto multiplico el valor del de la neurona anterior para dársela a comer a esta. Esos numeritos que dicen ahí W1, WN es lo que llamamos nosotros los parámetros. Eso no lo escuchamos nunca, porque este modelo de lenguaje es de 3 billones de parámetros, 15 billones de parámetros, 175 billones de parámetros. Los billones de parámetros en realidad son eso, son números enteros o números flotantes en realidad, números o coma que están guardados y que hacen esa multiplicación y suma y que el resultado de todo ese cálculo es la próxima generación de la próxima palabra, por ejemplo.
Parte 2: Próximamente.